
Features • Performance • Disk Space • Time Savings • File Integrity • Versions
FAST c/s, the File Analysis and Sizing Tool, is a system utility created by Fitzgerald & Long which reduces the staff time required for file maintenance, and ensures maximum system performance and efficient use of disk space. This robust utility was first written by Jeff Fitzgerald and Dr. Peggy Long in 1983 for Prime INFORMATION and was converted to support uniVerse in 1990. Today, there are over 2,270 FAST c/s user sites worldwide.
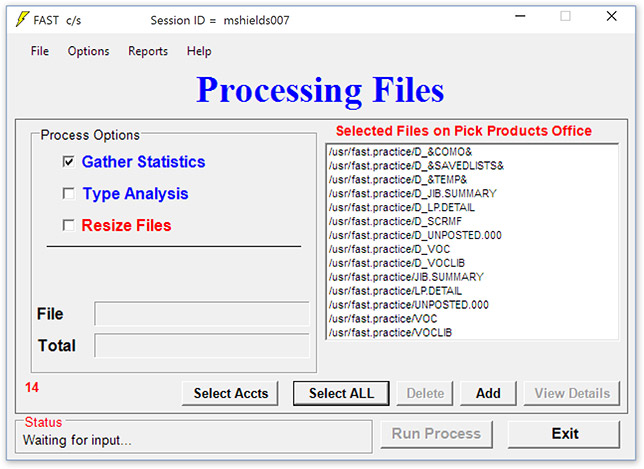 This client/server version, FAST c/s for uniVerse on UNIX offers a Windows™-based user interface. If you're familiar with point and click, list boxes etc., FAST c/s will feel very natural; you simply select the account or file you wish to analyze and FAST c/s performs it's three primary tasks: 1) file storage reporting, 2) optimum file type and modulo selection, and 3) automated file resizing. This gives you the best system performance available today. As a FAST c/s client, you will receive installation media containing the latest HTML technology which includes our pop-up "COACH" that leads you step-by-step through each of the FAST c/s processes, comprehensive HELP, context sensitive HELP, and our on-line User Guide. New staff members can step in immediately and use FAST c/s.
This client/server version, FAST c/s for uniVerse on UNIX offers a Windows™-based user interface. If you're familiar with point and click, list boxes etc., FAST c/s will feel very natural; you simply select the account or file you wish to analyze and FAST c/s performs it's three primary tasks: 1) file storage reporting, 2) optimum file type and modulo selection, and 3) automated file resizing. This gives you the best system performance available today. As a FAST c/s client, you will receive installation media containing the latest HTML technology which includes our pop-up "COACH" that leads you step-by-step through each of the FAST c/s processes, comprehensive HELP, context sensitive HELP, and our on-line User Guide. New staff members can step in immediately and use FAST c/s.
FAST c/s fully automates the resize function, based on accurate information and careful assessment of the current file structure. In addition, FAST c/s reports on file integrity, pinpointing possible damage in time for the user to take corrective action. FAST c/s produces easy to read reports providing a full statistical analysis including modulo recommendations. When needed, FAST c/s performs type analysis, choosing a new file type based on actual modeling of all 17 hashing algorithms. FAST c/s gives you the ability to access your internal network and run from any location. Users may schedule task execution to fit their operational schedule, our start/stop clocks make processing easy. The user retains complete control of the process and can override the FAST c/s recommendations or alter the list of files to be resized.
FAST c/s provides three core functions:
Gather Statistics — Collects current data describing each file, including type, modulo, separation and numerous other statistics. Recommends the best modulo for each file and evaluates the current type (hashing algorithm). Validates file integrity, producing diagnostics with specific information about any corruption found in any file. Produces a database from which a file statistics report is generated.
Type Analysis — Performs a simulation (in memory), trying each of the 17 possible file types and scoring them based upon the efficiency of the resulting data distribution. Only the files identified as having less than optimum hashing are processed. Because FAST c/s uses a simulation to model the types and doesn't rely upon trying to analyze the record keys, the results are superior to standard tools.
Automated Resizing — Using the uniVerse RESIZE verb FAST c/s will resize the files that require it, using the recommended modulo and type from the first two steps. The resize is controlled, allowing the user to specify a starting and/or stopping time for the process. Resizing may be done as a phantom or background process. A complete audit trail is maintained allowing easy evaluation of time requirements and any errors which may occur.
Hashed files are perfect for supporting a database because they allow rapid access to variable length records with widely ranging keys and data. However, there is a price to pay — maintenance is required to keep hashed files performing at peak efficiency. As data records are added to the file, the groups of the file fill up and the additional data is stored in overflow buffers. As more and more data is added, the chain of overflow can become very long. Retrieving and/or updating data records which are stored in overflow takes more system resource (disk I/O, CPU and memory!).
When a hashed file has become inefficiently structured, it must be resized to gain back performance. Resizing changes the modulo, type (hashing algorithm) and separation of the file to more appropriate values.
Of course, once the files are resized normal user activities will add, delete and update more records, causing the efficiency gained by resizing to be temporary. Just like changing the oil in your car, file resizing must be done regularly to maintain performance.
You would think that badly sized files would take up less space than properly sized ones; at least we did at first. However, the truth is that badly sized files very often waste disk space. The file may be taking up more space than needed because the modulo was made too big — often this happens due to poor analysis tools, because the administrator wanted to buy time before the next resize was required (anyone who has ever resized manually can see why the temptation exists to put off doing it!) or to compensate for a poor type choice. An inappropriate choice of separation very often leads to huge amounts of wasted space in some files.
FAST c/s will choose parameters for files which result in the best performance and most efficient use of disk space possible. The user may set control parameters which make FAST c/s "smarter" about certain files and their needs. You may control the amount of available space left for future growth, the "trigger point" for type analysis and a minimum modulo for files which contract and expand dynamically. And, of course, you may always override FAST c/s's recommendations
Anyone who has ever resized files manually is struck by how much time it takes — especially the analysis required to arrive at the appropriate modulo, type and separation. If the standard tools are used this tedious process must be done manually file-by-file. Even more time is required if the user chooses to test the recommendations before implementing them.
If you are amazingly quick, you might be able to complete the analysis of a small file in fifteen minutes. If your system has 500 files (most actually have more — data files, dictionaries, cross reference files, etc.) it will take you 125 hours to complete the task!! No wonder that most people choose to just hit the "hot spots" when resizing manually — it is nearly impossible to perform a thorough job.
What other tasks could you perform if you didn't have to spend this time resizing files? What performance gains would your users see if you could do a thorough job of resizing on a regular basis?
The internal structure of a hashed file is rather elegant. Each group's beginning may be calculated and accessed directly. However, within each group the data records are stored in a linked list. Each record has a header which contains information about that record, the location of the previous record and the location of the next record. When the database program retrieves a record from a group it follows the links from record to record within the group.
If a system problem occurs while a group is being updated, the links may be damaged so that they cannot be followed. This can result in lost data, aborts within your application and erroneous reports. Files with a great deal of overflow tend to be more vulnerable to damage if a system problem occurs. So, proper and regular resizing of your files will reduce your exposure (so will a reliable UPS!).
Should your system have a problem, how will you go about validating file integrity to insure that no files are damaged? Most administrators simply don't because there is not a reliable method of doing so. Counting the records in a file will find most, but not all, damage. The UNIX fschk utility will fix the files from the UNIX point of view, but may make the problem worse from the database's point of view.
The Gather Statistics process within FAST c/s follows the chain of records and groups within each file and checks for damage or inconsistency. Any problem is reported to you along with the type of problem, the group number and the location within the file where the damage is seen. While FAST c/s doesn't currently fix damaged files (this may become a future capability!) it makes you aware of any damage before it can get worse.
FAST c/s is available for uniVerse on Unix and Windows, UniData on Unix and Windows, and Prime INFORMATION.

